排序算法
排序算法
冒泡排序
思路:遍历第 0 个元素到第 n - 1 个元素,比较第i个元素与第i+1个元素,每轮遍历都能将最小(大)元素放至头(尾),这个过程就像冒泡一样。
1 | |
最快的情况是已有序,最慢的情况是逆序,平均时间复杂度是O(n2),是一种稳定的排序算法
可优化的做法是通过flag判断是否已经有序,有序时则可早退
选择排序
思路:每次遍历在未排序序列中选出最小(大)的数放置到已排序序列的末尾
1 | |
时间复杂度为O(n2),选择排序并不稳定,如[3, 5, 5, 4],就会改变两个5的相对位置。适用于小型数据集排序
插入排序
思路:分为未排序序列和已排序序列,将未排列序列逐一插入到已排序序列中的相应位置
1 | |
时间复杂度为O(n2),不需要额外内存来存储中间结果,是稳定的排序算法。适用于规模较小的排序序列
希尔排序
也称递减增量排序,将序列分成更小的序列,然后对小序列使用插入排序,从而减小排序列表交换次数。非稳定排序
首先定义一个增量序列的整数序列,用于确定子序列大小,最常用的增量序列是Knuth序列
1 | |
以增量序列为步长,从最大增量开始,向下迭代到最小增量
1 | |
归并排序
思路:基于分而治之的思想,将序列不断细分,细分成只有一个或两个元素的子序列,排序好后再合并回原来规模的序列。不需要交换比较,需要创建一个临时数组保存结果
递归法
1 | |
优化1:用不同方法处理小规模问题,减少函数调用次数:在小数组上用插入排序,if(en - st <= 10){Insert_sort(vector<int>& nums, int st, int en);}
优化2:剪枝,在合并前先判断两个子序列是否已经有序,即nums[st] < ... < nums[mid] < ... < nums[en]
时间复杂度为O(nlogn),空间复杂度为O(n)
迭代法
1 | |
时间复杂度是O(nlogn),避免了递归调用产生的栈空间消耗,适用于处理大规模数据,特别是可以通过并行化加快排序过程。归并排序是稳定排序
快速排序
思路:选出一个元素称为基准元素,将所有比基准值小的移动到基准左边,比基准值大的移动到右边,最后递归地把两边的子序列排序
1 | |
时间复杂度O(nlogn),就地排序,容易并行化
堆排序
先创建一个堆,不断把堆首元素与堆尾互换,再调整堆,保证堆首的一直都是未排序的最大值,
1 | |
堆排序的平均时间复杂度为 Ο(nlogn)
计数排序
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 Θ(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法
思路:找出待排序数组中的最大和最小元素,创建大小为 k=max−min+1的计数数组,记录数组中每个元素值出现次数,反向填充目标数组
1 | |
时间复杂度:O(n+k),其中 n 是数组的长度,k 是元素的范围。空间复杂度:O(k+n),需要额外的计数数组和输出数组。
从后向前遍历原数组,确保排序的稳定性,适用于元素范围较小的情况
桶排序
桶排序是计数排序的改进版,利用函数映射关系与桶对应,而不是根据元素大小开辟数组
思路:设定定量的数组当空桶,遍历序列一一放置到对应的桶中,对非空桶进行排序,最后放置回原数组
1 | |
桶排序的平均时间复杂度是 O(n+k),其中 n 是元素个数,k 是桶的数量。如果元素均匀分布,排序时间为O(n),最坏情况下,所有元素落入一个桶中,时间复杂度退化为O(nlogn)
基数排序
思路:将整数按位数切割成不同的数字,然后按每个位数分别比较
1 | |
位图排序
思路:根据待排序序列中最大的数,开辟一个数组或用bitset表示,每一位表示对应整数出现的次数
只需要遍历一次就能完成排序,输出排序后的结果
1 | |
适用场景:不重复的序列,快速判断一个数是否出现在序列当中,或者判断一个数是否会重复出现。用作排序,需要知道序列在一个大概的范围当中
总结
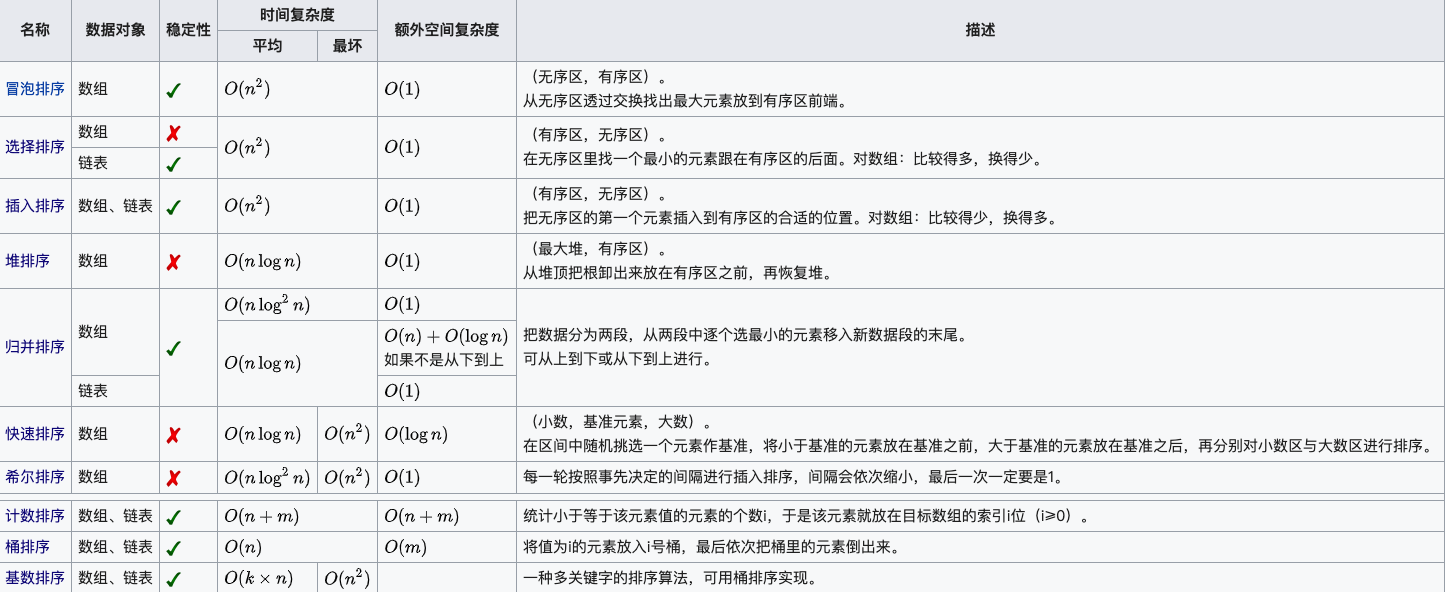
基于非比较的算法:计数排序、桶排序、基数排序,通常非比较的算法时间复杂度会更快, 基于比较的算法时间复杂度上限是O(nlogn)
就地排序算法:冒泡排序、选择排序、插入排序、对排序、希尔排序
稳定排序算法:冒泡排序、插入排序、归并排序、基数排序
非稳定排序算法:选择排序、快速排序、希尔排序、堆排序
外部排序算法:归并排序、基数排序、堆排序、桶排序
注
C++中的std::sort
std::sort的底层实现原理是introspective Sort内省排序实现,结合了快排、堆排和插入排序的优点
std::sort的具体步骤:对整个数组进行快速排序 ,当快排的递归深度超过log(n)时,就会切换到堆排序,避免了快排的最坏情况下的性能问题,当子数组的规模较小时,使用插入排序来提高性能
1 | |
C++ 中的std::stable_sort函数
std::stable_sort函数通常由归并排序实现,标准库对归并排序有多种优化,以提高缓存局部性和减少内存分配次数,如使用自底向上的归并排序和内省策略来选择合适的排序方法
1 | |